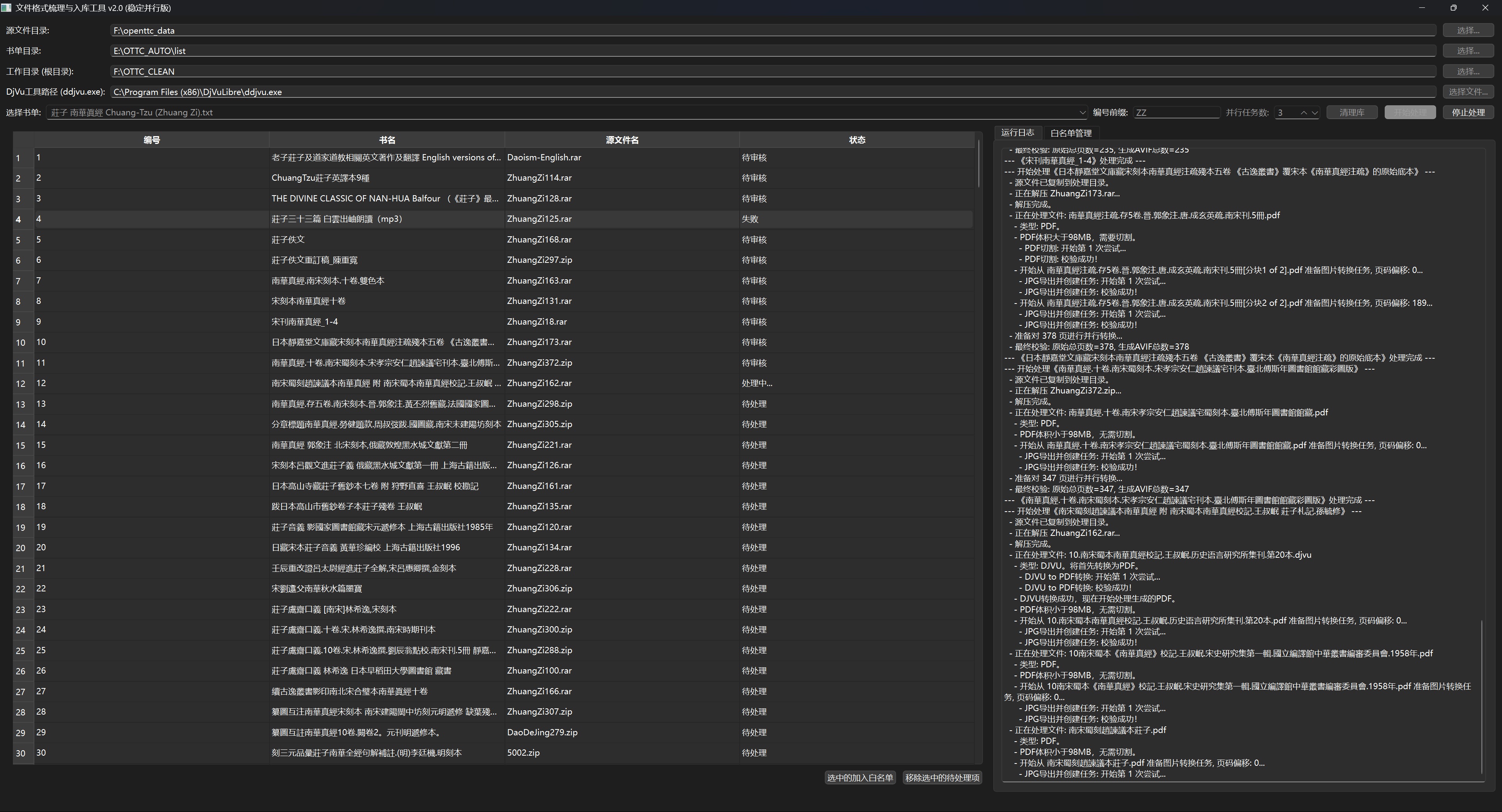
4500多个压缩包,近6000本书。
写了个脚本,自动转格式。
路漫漫其修远兮……
转完了再通过脚本上传。
这个是脚本上传的: https://openttc.com/t/topic/74/64
但是有些书籍有3000多页。冷静…
4500多个压缩包,近6000本书。
写了个脚本,自动转格式。
路漫漫其修远兮……
转完了再通过脚本上传。
这个是脚本上传的: https://openttc.com/t/topic/74/64
但是有些书籍有3000多页。冷静…
你这个项目有意义啊
话说有没有葵花宝典?
有很多不必伤害自己的修仙宝典 XD
春宫图什么的 可以用来引流
啊…… 美色 只会阻挡我飞升的脚步 XD
分享一份吧
你都看完了 飞升完了吧
过两天都会上传的 欢迎阅读
看不完,太多了。文言文好比是超级压缩包,理解起来晦涩难懂。
我只是个图书馆管理员。
网址呢?
估计还要30天左右,数据理好。再上传。
@秦始黄正黄 站长,这种Discourse大规模文件上传的解决方案你了解不。目前我想用的方法是用API接入脚本的方式,自动化运行。但是实测下来效率不高。很容易撞服务器429。将近一百万张图片,一张一张上传比较慢的。或者我整个上传到s3,再解压。然后按套路列好URL,再用脚本到Discourse上复制URL批量发贴。这样效率能有提升,但还是比较慢。要不直接改数据库?我日,好想法。我去琢磨琢磨。
Ai给出的解决方案:
如果您能直接 SSH 登录到 Discourse 服务器,并且有技术能力,直接在 Rails Console 中执行代码是最快、最彻底绕过 HTTP API 限速的方法。
1.登录到容器:
cd /var/discourse
./launcher enter app
rails c
2.禁用限速器 (RateLimiter): 在 Rails Console 中,您可以完全禁用业务逻辑中的限速器,并在脚本中直接调用内部的 PostCreator 和 TopicCreator 类。
# 在导入代码块的开头 RateLimiter.disable do # 您的 Ruby 导入逻辑在这里 # 直接调用 PostCreator.create! 等方法 # 这样就不会触发任何 API 限速 end
3.创建导入脚本: 您将编写一个 Ruby 脚本,该脚本读取您的映射文件(文件夹/图片列表),然后使用 Ruby 代码直接创建 Topic 和 Post,而不是通过 HTTP API。
例如:使用 TopicCreator.create!(user, title: "...", raw: "...")。
图片上传: 同样,您将使用内部的 UploadCreator 或直接操作文件系统和数据库,而非 uploads.json 接口。
优点: 速度最快,可以处理您的数十万数据,且无需担心 429 错误。
缺点: 要求您对 Ruby 语言和 Discourse 的内部数据结构/类有一定的了解。
我一本书都没看到。
我靠。
批量传,不得传一个月?
估计传不完。数量太多了。肯定是要好好想想办法的。
邮寄硬盘吧 国内有些机房是可以自己加硬盘的 嘿嘿
牛批。